Concurrency and Multithreading in Python
Both in software and in the real world, there are many types of processes with steps that can be executed concurrently. Consider for example if you're cooking dinner, you can boil water, preheat the oven, and chop vegetables at the same time. Performing these steps in parallel is so obvious that it would feel foolish to complete each task end-to-end one after another. The same can be said about many types of processes in software, which makes concurrency—and recognizing when to use it—a very powerful tool to have at your disposal. In this blog post, I explore the concept of concurrency and provide some examples of multithreaded code in Python.
Threads
Consider the following python script: hello.py.
import os
import threading
if __name__ == '__main__':
print(os.getpid())
print(threading.current_thread().name)
print("Hello World!")When I run python3 hello.py, my operating system creates a process with a PID which runs the script. On execution, the Python interpreter creates a main thread to read and execute the code line by line, giving the following output:
215826
MainThread
Hello World!The process has a PID of 215826, and a single thread with the name MainThread. This one-to-one relationship of process to thread is the default in Python and most languages, but it is not a requirement. We can use multithreading to create many more threads in addition to our MainThread, forming a one-to-many relationship between the parent process and the child threads. Each thread has its own registers and call stack, but shares the same heap and source code as all other threads.
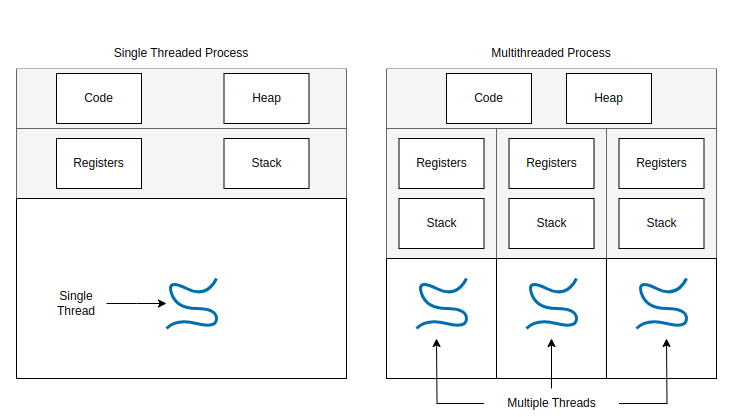
Multithreading
Let's create a basic class with a thread pool and a shared counter. We'll add an increment method to sleep for 1 second, increment the shared counter, and print the current count. Our script will create a thread pool, and call increment for each thread based on a thread_count argument. I've added --lock and --wait arguments as well; we will come back to these later.
import concurrent.futures
import threading
import argparse
import time
class ThreadPool:
def __init__(self, num_threads):
self.num_threads = num_threads
self.count = 0
self.pool = concurrent.futures.ThreadPoolExecutor(max_workers=num_threads)
self.lock = threading.Lock()
def increment(self):
time.sleep(1)
self.count += 1
print(self.count)
def increment_with_lock(self):
time.sleep(1)
with self.lock:
self.count += 1
print(self.count)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Processing CLI args.")Let's test out our script with a few different arguments for thread_count and compare the runtime and output.
%time !python3 threads.py 1
done
1
CPU times: user 46 ms, sys: 23.7 ms, total: 69.8 ms
Wall time: 1.19 s%time !python3 threads.py 10
done
1
2
3
4
6
8
5
7
10
9
CPU times: user 62.3 ms, sys: 17.4 ms, total: 79.8 ms
Wall time: 1.2 s%time !python3 threads.py 1000
done
1
2
3
[...]
695
450
349
CPU times: user 134 ms, sys: 16.5 ms, total: 150 ms
Wall time: 1.35 sRight away we can notice some very interesting behavior.
First, the runtime for one thread is the same as the runtime for many threads! This is because the main thread kicks off each of the worker threads, which execute concurrently, so the 1 second sleep happens at the same time for every thread. If we were to run the same code serially with n threads, where we sleep for a second, increment a counter, and print the count, our runtime would be n seconds. Instead, since we are running the code in parallel, the runtime is just about 1 second, even up to 1000 threads!
We are however, subject to some limitations. The bottleneck here is the resource and memory overhead required to manage many threads.
Non-Deterministic Execution and Race Conditions
Another interesting piece is the order of the printed output.
Let's run our script again with 10 threads.
%time !python3 threads.py 10
done
1
2
3
5
7
4
10
6
8
9
CPU times: user 64.2 ms, sys: 17.1 ms, total: 81.3 ms
Wall time: 1.21 sNotice how the output is not in numerical order. If we rerun the script we will get a different output order each time. This is known as non-deterministic execution. Multithreaded execution involves rapidly alternating between threads across a single processor to allow threads to make progress concurrently.
This results in an effect known as interleaving which causes threads to finish in a different order on each execution. In this case, interleaving introduces a race condition to our code, since multiple threads are "racing" to increment, access, and print the shared counter variable.

Race conditions are a very common problem in concurrent programming. One of the ways to avoid race conditions is to add a lock on code that updates a shared state. In our example, this would mean adding a lock on the code to increment and print the counter. The block of code inside the lock will be executed serially to avoid any unwanted consequences of interleaving.
Let's pass in the --lock parameter to our script above and see how the output changes.
!python3 threads.py 10 --lock
done
1
2
3
4
5
6
7
8
9
10Now we can see that the threads are always printing the output in the correct order. We are able to do this without sacrificing the runtime gains, since we are executing the sleep before the lock.
Blocking on Thread Execution
The final point of interest in our output above is the ordering of the "done" statement. We can see that "done" is actually printed first out of all our output. Based on our script, "done" should be printed last. The reason for this mismatch is that we are setting the wait parameter in the threadpool.shutdown method to False by default. This parameter decides whether or not our script execution should block on the exeuction of our worker threads.
We can pass in the --wait arg to the above script, and now the "done" statement will appear at the end of our output.
!python3 threads.py 10 --lock --wait
1
2
3
4
5
6
7
8
9
10
doneConcurrency in Action: URL Health Checks with Async HTTP Requests
Of course, the example above of incrementing a counter with a sleep is trivial. The sleep is really just a placeholder for any real "work" that our multithreaded code might need to do.
Let's say for example, we want to do a health check on every three letter .com domain. We can check a single URL by making an HTTP head request and looking for a response with a 200 status code. We will also allow redirects to avoid getting 301 responses, and set a timeout of 5 seconds to prevent failed requests from hanging too long.
url = "https://aaa.com"
response = requests.head(url, allow_redirects=True, timeout=5)
if response.status_code == 200:
print("Healthy link!")Let's assume it takes about 1 second to make a single head request. If we want to check all three letter strings, we have 26^3 or 17,576 total URLs to check. If we check these URLs serially, this will take on average 17,576 seconds, or about 4.8 hours.
This is way too slow.
Using multithreading, we can do it in just a couple of minutes.
Generating The Links
First, we can easily generate our URLs using itertools to compute all three letter strings by taking the Cartesian product of the letters in the alphabet.
alphabet = [chr(i) for i in range(97, 123)]
urls = ['https://' + ''.join(prod) + '.com' for prod in itertools.product(alphabet, repeat=3)]We now have a list of the 17,576 unique three letter .com URLs.
Chunking URLs Across Threads
In a perfect world without any hardware constraints, we could spin up 17,576 unique threads and each thread could check a single URL. Of course, this is unrealistic for most hardware. Instead we will need to distribute the URLs among our threads. We can do this by dividing the number of URLs by the number of threads, and chunking the URLs into groups of that size. If we have a remainder, we can spread the remaining URLs out among the existing chunks. This way, we can test out different numbers of threads and always be sure the URLs are spread evenly.
Putting It All Together
We can repurpose our script from earlier to check URLs instead of increment a counter. We'll also add some logic to store the results in a CSV so we can take a look at the data.
import concurrent.futures
import time
import os
import threading
import argparse
import requests
from collections import defaultdict
import itertools
import csv
class ThreadPool:
def __init__(self, num_threads):
self.num_threads = num_threads
self.pool = concurrent.futures.ThreadPoolExecutor(max_workers=num_threads)
self.lock = threading.Lock()
self.urls = ['https://' + ''.join(prod) + '.com' for prod in itertools.product([chr(i) for i in range(97, 123)], repeat=3)]
self.successful = set()
self.failed = set()
self.exceptions = defaultdict(int)
self.timeout = 10
self.results = {url: {"status_code": "", "success": "", "exception": ""} for url in self.urls}
def check_url(self, url):
try:
response = requests.head(url, allow_redirects=True, timeout=self.timeout)Let's test our the script with a thread_count of 1000.
%time !python3 threads_http.py 1000
Chunking URLs into 1000 chunks with average size 17
Successful: 1, Failed: 0
[...]
Successful: 6625, Failed: 10951
done
See output.csv for more details
CPU times: user 13.5 s, sys: 2.15 s, total: 15.7 s
Wall time: 3min 36sOur script checked all 17,576 URLs in just 3 minutes and 36 seconds! This is 80x faster than the average runtime of doing this check serially!
Now let's see what happens with 100 threads.
%time !python3 threads_http.py 100
Chunking URLs into 100 chunks with average size 175
Successful: 0, Failed: 1
[...]
Successful: 6306, Failed: 11270
done
See output.csv for more details
CPU times: user 42.1 s, sys: 6.79 s, total: 48.9 s
Wall time: 11min 27sInterestingly, our runtime is much higher at 11 minutes and 27 seconds. While this is still about 25x faster than doing the checks serially, it is almost 3x slower than using 1000 threads. This highlights the importance of testing out different thread counts to find the optimal number of threads for your workload and whatever hardware you're using.
Looking at the Data
Now that we have a CSV of the results, we can take a closer look at the data. First we'll plot the distribution of unique status codes.
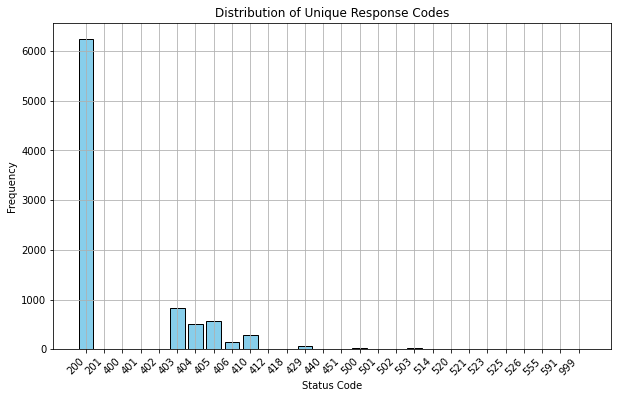
We can see the roughly 6,000 successful requests. Let's exclude those and hone in on the 400s and 500s.
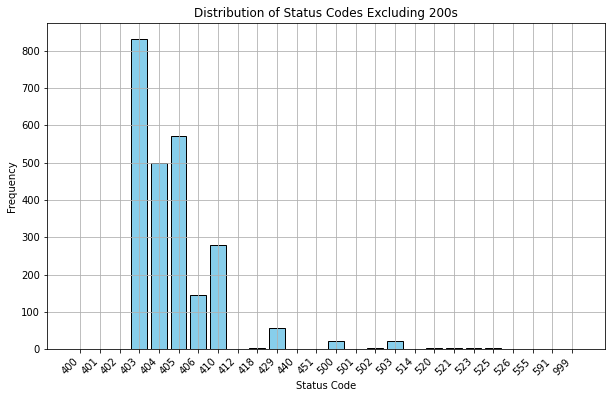
We can see that most of the failed status codes are 403, 404, 405, or 410 errors. We also got a few more obscure error codes, like 999, 591, 555, and even 418. See here for more details on HTTP status codes.
We can also plot the other type of failure, where our request throws an exception.
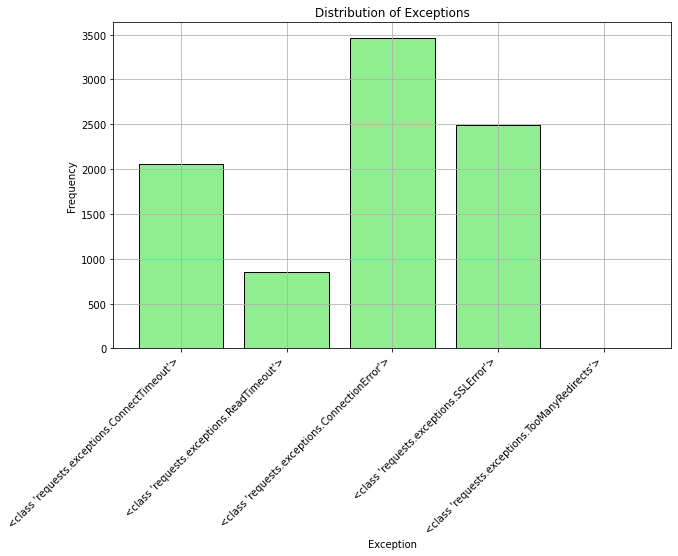
Most of the exceptions we hit were related to timeouts and SSL errors. This is probably due to the 5 second timeout we added, and the fact that we used https for all requests intead of just http. If we tweak the script to use a longer timeout period, I imagine the number of timeout exceptions would drop up to a certain point.
Wrapping Up
While this example of doing a health check on all 3 letter .com URLs is not super practical, the same setup can be used for any process that requires many async HTTP requests, database queries, or API calls.
The next time you find yourself waiting a while for your code to finish running, take a step back and consider if concurrency could speed things up. Oftentimes it can, and learning how to identify use cases for concurrency in your code is an important skill to build. Eventually it will start to become obvious, like boiling your water and preheating the oven while you chop vegetables.